2023年度,山东大学智能媒体研究中心(iLearn)研究团队,在视觉问答、情绪识别领域取得代表性原创成果,发表在CCF-A类学术会议:ACM MM、AAAI 上。参与本研究工作的研究生、本科生已推免至哈尔滨工业大学(深圳)、华东师范大学。
论文题目:《Unlocking the Power of Multimodal Learning for Emotion Recognition in Conversation》
作者:王蕴潇、刘萌 等
录用会议:International Conference on Multimedia (ACM MM 2023)
成果简介:对话情绪识别旨在辨识对话中每句话所蕴含的情感,在医疗保健、教育和服务等多个领域具有巨大的应用价值。除了单纯的语言元素,情感还通过一系列非语言指标来传达,如面部表情、音调变化和身体手势。因此,近期的许多研究工作已经采用了多模态信息来增强情绪识别的精度。然而,我们发现在对话情绪识别任务上,增加模态的数量并不能持续地提高模型的精度。通过实验验证,我们认为造成这一现象的原因是不同模态之间梯度的不平衡分配。为解决这一问题,我们提出了一种插件式的细粒度动态梯度调制方法,能在参数粒度上动态平衡不同模态之间的梯度分配,从而使所有模态均能得到充分的优化,以释放多模态数据的潜力。实验结果显示该方法显著改善了所有基准模型的性能,并优于现有插件方法

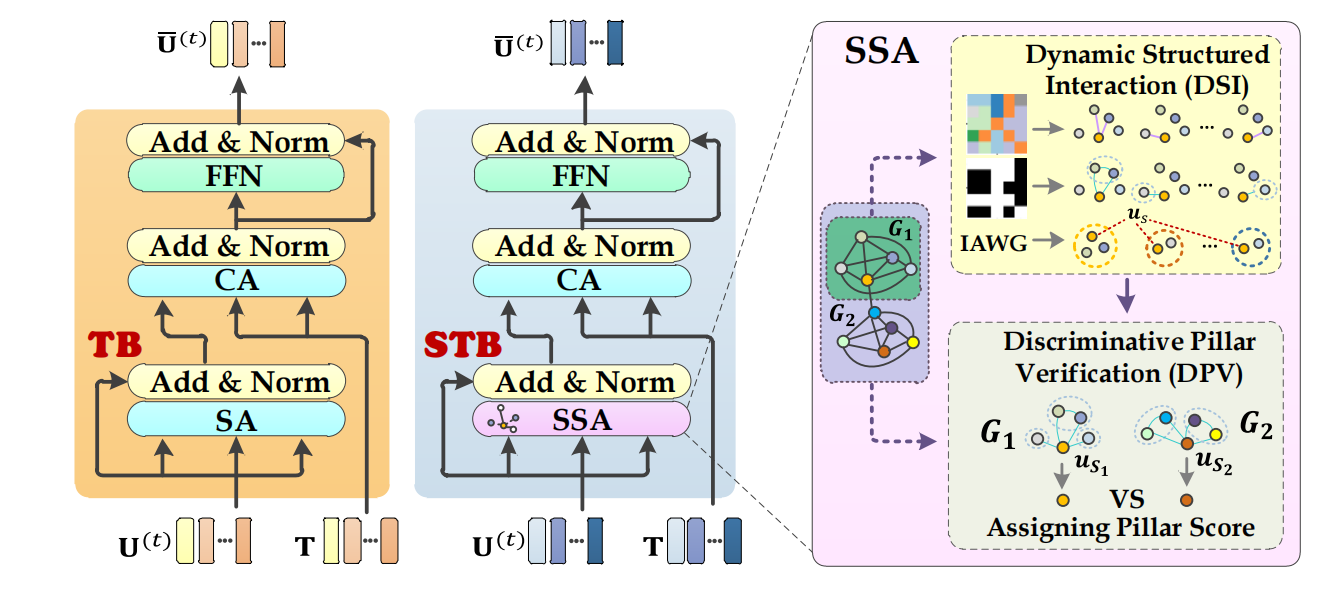
论文题目:《Exploiting the Social-like Prior in Transformer for Visual Reasoning》
作者:韩昱东、胡宇鹏 等
录用会议:AAAI Conference on Artificial Intelligence (AAAI 2024)
成果简介:为实现多模态任务视觉上下文学习过程中存在的秩塌陷和表征退化问题,本文受社交理论启发,利用结构洞和中心度实现了多模态推理中的结构化交互和语义判别建模,实现更加鲁棒性的多模态协同语义推理。